Parallel-capable netlist data structures, part 2
Issues with the current code
The throwaway code from last time has a few immediately-obvious issues:
The connect_*/disconnect_* abstractions aren't being used
These functions were pretty clearly suboptimal for the logic that was needed (disconnecting some existing connections and, at the same time, replacing them with connections to a newly-added cell).
This is a "simple matter of API design" that can be improved with new functions (such as explicit "swap" operations). As such, this can be deferred until "later."
Manually acquiring read/write guards and retrying operations
There are currently no abstractions to help with making sure the correct locks are acquired, causing the following issues:
-
Every single
try_read()andtry_write()manually handles errorsEvery single lock operation has to be manually followed by a check for an error, potentially re-queuing the current cell and continuing, and an
unwrap(). Messing this up will cause a hard-to-debug logic error (which happened at least once while I was writing the code). -
You need to commit to read vs. write ahead of time
If a read lock has already been acquired, there isn't any way to "upgrade" it to a write lock. It is also not possible to subsequently acquire a separate write lock (even on the same thread) because there are already readers.
-
There isn't any obvious way to extend this for algorithms that require ordering
In order to support "ordered" algorithms, we need some way to perform speculative execution but buffer the actual write/modify operations until the operation commits. (In the worst case, this might result in unavoidable serialization.) There isn't an obvious way to implement this, as the only boundary identifying the "actual writes" is currently a
// actual updatesline.
Properly encapsulating graph operations
Through discussing this API surface with a friend, we have collectively come up with the following design:
-
Operations are split into an explicit "read-only" phase and a "read-write" phase.
This commits us to the restriction of "all algorithms that the netlist API helps you with must be 'cautious' as defined in the Pingali et al. paper."
Because many (and likely most of the ones we will need) operations on netlists can indeed be rewritten into this form, I will consider this a perfectly acceptable trade-off in exchange for being able to speculatively execute operations concurrently.
With this split, it also becomes possible to defer the "read-write" phase to a later time when implementing an "ordered" algorithm. The following is one way to do that:
-
The data passed from the RO phase to the RW phase is explicitly stored into a
structwhich must beSend -
When the RO phase finishes, the RW phase isn't (necessarily) run immediately. Instead, this resulting
structis stored in some kind of commit pool. -
When the write is finally ready to commit, the RW phase is finally called (which can be from a different thread).
-
If the write is instead aborted, the RW phase is never run.
-
If an operation is instead unordered, the RW phase can be run immediately after the RO phase on the same thread, as an optimization.
There is a potential concern with this split: if the graph manipulating operator is "expensive" in some way, how should this cost be split? Should most of the work be performed in the read-only phase or the read-write phase? How much does this matter in practice? For now, I have chosen to ignore this problem.
-
-
The read-only phase (somehow) tells the framework which nodes will be written in the read-write phase. All locks acquired in the read-only phase will have one of the following states in the read-write phase: still read-only, upgraded to read-write, or released.
The framework will then automatically handle "upgrading" the required locks.
For an "unordered" algorithm, failure to upgrade a lock results in the current operation being abandoned and retried later.
For an "ordered" algorithm, something more complicated has to happen. The Kulkarni et al. paper explains one way to do this using iteration locks. (Note that that paper describes the commit pool as containing an undo log, rather than our implementation of storing a write callback and simply not doing the work until commit time.) This seems to make sense but requires a bunch more engineering effort, so I will simply hope that everything will work out in the end 🙃.
Okay, let's build it!
If we are going to separate out read-only and read-write phases, it would probably involve separating the phases into separate functions. In order to hold on to locks across them, we need a struct of some kind:
#[derive(Debug)]
pub struct CellLockWip<'a> {
idx: usize,
r: Option<RwLockReadGuard<'a, NetlistCell>>,
w: Option<RwLockWriteGuard<'a, NetlistCell>>,
}
And a corresponding function for acquiring a lock:
impl NetlistModule {
// ... other functions omitted
pub fn lock_cell_for_read_ro_phase(&self, idx: usize) -> Option<CellLockWip> {
let cell = self.cells.get(idx).unwrap();
Some(CellLockWip {
idx,
r: Some(cell.try_read().ok()?),
w: None,
})
}
}
Hmm, it doesn't work though...
error[E0515]: cannot return value referencing local variable `cell`
--> sicl4_db/src/test_slab_nonblock.rs:167:9
|
167 | / Some(CellLockWip {
168 | | idx,
169 | | r: Some(cell.try_read().ok()?),
| | ---- `cell` is borrowed here
170 | | w: None,
171 | | })
| |__________^ returns a value referencing data owned by the current function
It turns out that no amount of trying to hack around this can make this work. The description of sharded_slab::Entry actually explains why, but I failed to realize the implications.
In a sharded_slab, it is possible for another thread to attempt to free an item that the current thread is still working on. A sharded_slab::Entry prevents this from causing problems by deferring the free until all guards are dropped. In my code, I had been making an implicit assumption that freeing an entry is only possible with a write guard held (i.e. the current thread is the only one that can possibly see the node to be freed). However, the sharded_slab crate knows nothing about the locking I am doing.
It seems like trying to hang on to both the Entry and RwLock*Guard objects should work in theory, but the limitations of the Rust borrow checker prevent this (the RwLock guard lifetime needs to be at least as long as the Entry lifetime, but this would result in a self-referential struct).
The Kulkarni et al. paper also happens to mention that freeing entries should only happen when a write operation commits. I had not considered that I would need to actually enforce this.
Solving these problems seems like it will require tighter integration between our locking rules and our memory allocator. It looks like I need to actually start implementing all of the data structures I need "for real" instead of trying to quickly duct-tape together existing pieces that only approximately do what I want.
However, at this point, it would appear that I have a decent idea what exactly I would even need to implement:
- Netlist nodes are stored in an arena, "essentially a way to group up allocations that are expected to have the same lifetime"
- The framework needs to somehow own/control/manage its own per-node reader-writer locks
- This is needed for the aforementioned object freeing issue
- The framework needs to know about locks in order to deal with algorithms requiring order
- Allowing the netlist framework to have visibility into locks potentially allows for more advanced work scheduling in the future
- A work-stealing task queue (possibly by reusing an existing one, but it needs to know what to do with speculatively executing ordered algorithms)
- Probably a slab allocator, for memory locality and to avoid hitting the system allocator extremely hard
- Actually build out proper APIs mentioned at the very beginning of this article
- Actually build out a proper "wire" and "port <-> wire" system like Yosys's
Okay, now let's build it!
Memory allocator
The lowest-level part of building everything "for real" is memory allocation. The internal implementation of the sharded_slab crate is inspired by a technical report from Microsoft Research entitled "Mimalloc: Free List Sharding in Action".
I spent quite some time pouring over this paper. I am not very good at serializing these thoughts into a blog post, so here is a brain dump:
- We don't need a general-purpose malloc, only a closed set of types of known sizes, so we don't need the
pages_direct/pageslists. - Q: Why does Mimalloc need three free lists, but
sharded_slabonly has two? A: With thesharded_slabimplementation, the "deterministic heartbeat" functionality is lost.- What is Mimalloc amortizing with its deterministic heartbeat?
- Batching frees for dynamic languages — not something that we need
- Returning memory to the operating system — unclear whether or not we will be doing that
- Collecting the remote thread free lists
- Collecting the thread delayed free blocks, thus moving pages off of the full list. This one is really important. Although the idea is conceptually very simple (do not waste time searching for available blocks in pages that are completely full), the introduction of the full list optimization significantly increases the engineering complexity of the allocator and required wrapping my head around far more complexity than without it.
- What is Mimalloc amortizing with its deterministic heartbeat?
- Q: What if we don't amortize with a deterministic heartbeat? I.e. what if we instead perform local frees directly onto the one singular local free list, and only perform deferred operations after a thread completely runs out of local space?
- A: I don't have any proper proof of bounds here, but gut-feeling/intuition seems to be saying that it probably will not be big-O worse. (I tried to think of any possible pathological way to cause this style of memory allocator to end up in a situation of "each netlist node has a netlist's worth of wasted space (i.e. freed by remote threads but not reclaimed) between it and the next node" but could not come up with a way to do that unless the algorithm inherently requires that much temporary space, in which case the blame isn't on the allocator.) However, not having a deterministic heartbeat can make the variance in allocation time much worse, which seems like it's probably by itself undesirable.
- Q: What is the Mimalloc paper talking about when it mentions the
DELAYEDvsDELAYINGstates? Why do we need that?- First of all, this part of the paper doesn't match the actual published code.
The code has at least one further optimization: a block will not be put on the thread delayed free list if another block in the same page is already on said list. This is because only one block per page is needed in order for the owning thread to eventually realize that the page isn't full anymore.This optimization is actually given two sentences in the paper which I initially overlooked. The paper still does not match the published code which contains an additional "never delayed free" state that I also don't fully understand. - A: I don't fully understand this, but it has to do with thread termination. When a thread terminates in Mimalloc, its owned pages are somehow "given" to another thread or something. We will probably just... not do that, but our implementation does still need to figure out its thread lifetime story at some point though. Note from the future: we actually end up reinventing the entire set of state transitions used to manage the full list.
- First of all, this part of the paper doesn't match the actual published code.
Okay, let's hack together the fast path. Here we go! There's not much to say about this, it's just writing unsafe Rust code as if it were C-like.
But wow, this is an awful mess of pointer casting, TODOs, FIXMEs, XXXs, and general jank.
Fixing the "complicated Rust stuff"
The following things need to be fixed immediately:
- Having an invariant "arena" lifetime as described in this article
- In the meantime, figuring out the correct variance story around
T - ... which, while we're at it, requires figuring out all of the other things mentioned in the
PhantomDatanomicon article: drop check andSend/Sync - ... which (among other things) requires figuring out the thread creation / termination story
Rust: forcing you to design APIs properly!
So, how do we want our framework to work? Have another brain dump:
Graph node objects must beGraph node objects must be bothSend. This is a hard requirement, as we will be (potentially) processing data across different threads. TheT: Sendbound that the hacked-together code has is correct and is the same as what Rust requires for e.g.Arc<Mutex<T>>.SendandSync.Sendis required because we will be (potentially) processing data across different threads.Syncis also required because multiple read guards can exist at the same time, across separate threads, meaning there can be multiple&references at the same time. There can still only be one&mutreference at once, and any potential interior mutability is the responsibility of the node types to make safe, not the allocator/locking.- The "root" heap object is somehow used to create per-thread state, which is then used to allocate/free data. This is currently
SlabAllocandSlabThreadState, but these types are definitely borked in the hack implementation. - The general program flow envisioned is something like:
- Run a graph algorithm, across every CPU core
- Wait for everything to finish
- Threads terminate when there is no more work
- Possibly(???) optimize memory usage/fragmentation/balancing-across-threads (is this useful at all?)
- Run the next graph algorithm
- Does the "root" object need to be
Sync? If it is, then threads can freely spawn subthreads with their own heap shards. If it is not, then one initial thread must set up all the necessary shards before launching work threads. - Does the "root" object need to be
Send? As far as I can tell, no. But it probably should be. - Does the per-thread object need to be
Sync? It CANNOT be. The whole point of it is that it belongs to one specific thread. - Does the per-thread object need to be
Send? If the "root" object is notSync, this object must beSend(or else it wouldn't be possible to give it to worker threads). Otherwise, no (e.g. if using OS TLS primitives?). - Do node read/write guard objects need to be
Send/Sync? They again cannot beSync, as they belong to one specific thread. Having them beSendfeels somewhat wrong, but isn't blatantly unsafe (e.g. a graph algorithm creates subthreads and gives them the guard object)?is conceptually required, as the way an "ordered" graph algorithm will work involves leaving graph nodes locked after its read-only phase finishes until the read-write phase eventually either commits or abandons. That can happen on an entirely different thread from the read-only phase. - Guard objects cannot outlive segments/pages.
- Nothing can outlive the "root" object.
- In general, what are we actually trying to check wrt object lifetimes?
- Don't cause memory safety issues when deleting nodes
- Prevent graph manipulating code from stashing references/guards for graph nodes and accessing them after the algorithm should have finished
- i.e. so that we can safely do the "optimize/defragment memory" operation
- I fundamentally do not have good enough intuition on the behavior of
&'a TvsT<'a>vs&'a T<'b>- We need good intuition about this in order to understand whether or not we should be covariant or invariant over
T, especially since we will be using interior mutability.
- We need good intuition about this in order to understand whether or not we should be covariant or invariant over
- I don't understand the nomicon chapter on
PhantomDatadrop check at all.
After thinking through all of this and several days of hacking later, we now have this!
What did we learn?
It's hard to transfer intuition across brains, but here's another brain dump:
- As updated above,
Tneeds to be bothSendandSync. - We've created a "root" object that is both
SendandSync.- However, as soon as
new_threadis ever called on it, the object becomes pinned in memory. This inherently has to happen: segments contain a pointer back to the per-thread state, and so the per-thread state cannot move anymore. This doesn't actually affect whether or not the root object isSendthough: transferring the ownership (without moving it) should still work without issue (although we haven't actually tested whether Rust will allow us to write code that does anything like that).
- However, as soon as
- The variance on
Tseems like it should be covariance. The nomicon states "as soon as you try to stuff them in something like a mutable reference, they inherit invariance and you're prevented from doing anything bad." The following is a worked example of how that is supposed to work:
We have code that, oversimplified, will eventually look like the following:
struct SlabThreadShard<'arena, T> { /* stuff */ }
struct LockGuard<'arena, T> { /* stuff */ }
impl<'arena, T> SlabThreadShard<'arena, T> {
fn lock_an_object(&'arena self, obj: /* some kind of ref */) -> LockGuard<'arena, T> {
/* impl */
}
}
impl<'arena, T> Deref for LockGuard<'arena, T> {
type Target = T;
fn deref<'guard>(&'guard self) -> &'guard T { /* impl */ }
}
impl<'arena, T> DerefMut for LockGuard<'arena, T> {
fn deref_mut<'guard>(&'guard mut self) -> &'guard mut T { /* impl */ }
}
// users cannot access data outside of the lifetime of 'guard
// 'guard cannot be longer than 'arena
In the deref_mut function, if we let T = &'a U, the function signature becomes
fn deref_mut<'guard>(&'guard mut self) -> &'guard mut &'a U
Because &'a mut T is invariant over T, &'guard mut &'a U forces anything that might be stored to be exactly &'a U.
However, I still haven't tested any of this. There might still be something I've missed.
- I still don't understand drop check and haven't gotten around to implementing any code to support dropping yet.
- The most useful articles for building my intuition about memory ordering were:
- https://preshing.com/20120710/memory-barriers-are-like-source-control-operations/
- https://preshing.com/20120913/acquire-and-release-semantics/ (specifically the diagrams with the square brackets indicating across where memory operations cannot move)
- https://preshing.com/20130823/the-synchronizes-with-relation/ explaining synchronizes-with.
- Our thread creation / termination story is as follows: The heap can only support a hardcoded maximum number of threads. If a thread terminates, nothing happens to any of its memory and none of it is freed. Other threads can keep accessing nodes that exist on its pages. Other threads can also free nodes that exist on the terminated thread's pages, but nothing will ever come around to sweep/collect them anymore. When a thread is created, the code first tries to find an existing "abandoned" set of memory and gives this new thread that memory (only creating a totally new thread shard if that fails). With the envisioned execution model, this should be totally fine — we will grab
nthreads, do stuff, drop allnthreads, and then pick up the samenthread shards (and associated memory) the next time we do stuff.
Netlist and object locking
After building the allocator, we need to build this next.
I'm quite familiar with atomic operations and locking (other than memory ordering), so this is quite straightforward after all of the struggles of the previous section. Here we go, and here we have a port of the previous benchmark.
While writing this, I noticed the following concerns:
- Guards aren't required to outlive the per-thread handle. This seems
// XXX XXX XXX BAD BAD BAD ???, but I need to understand and be able to explain why. - I am using a nasty trick to deal with attempting to get a lock on an object that has been deallocated. It is not clear to me whether or not this is UB according to any theoretical memory models (it definitely does end up mixing atomic (read/write lock guard) and non-atomic (free list) access to the same address) or in practice. This definitely needs to be fixed (or at least reasoned through).
- I don't have a full intuitive understanding of Rust's UB rules regarding summoning up
mutpointers/references derived from a&reference. - Variance really matters here as netlist cells/wires... have lifetime params. I still haven't tried intentionally breaking it (although doing the "normal/intended" thing is accepted).
- This new API has way less locking-related noise compared to the previous duct-tape attempts. This is definitely better.
Let's fix some of these issues:
Surprisingly to me at first, there is no issue with having read/write guards outlive the heap thread shard. This is because the heap thread shard controls the ability to perform allocator activity (i.e. allocating and freeing), whereas the read/write guards control the ability to perform netlist content activity (i.e. scribbling all over graph nodes).
... actually, that makes perfect sense now that it is all spelled out. Once you've gotten memory from e.g. malloc, you are free to do whatever you want as far as the heap is concerned. The heap only needs to protect itself from concurrency issues, and you can't allocate/free anything if you don't have a heap shard.
Which means that I should probably work out and explicitly spell out the coupling I actually need between the allocator and the locking logic:
- the ability to deallocate through a write guard. We can do this whereas Rust's
RwLockWriteGuardcan't because we know that the object we are protecting came from our special heap, whereas aRwLock<T>can be stored anywhere and not even necessarily in a heap allocation. - our heap allows us to very very carefully access deallocated objects, using the hack of overlaying the lock/generation counter with the free list next pointer. Not only do we know that the backing memory segment itself cannot disappear, we've also gained the ability to logically invalidate old pointers to the freed node, without having to go through connected graph nodes to erase the pointers.
- we want to be able to define periods in the code where neither allocator nor netlist activity are happening. We can couple these together on purpose even though there is no need to do so for safety (by adding a
PhantomDatainside the read/write guards borrowing the thread shard).
This is good intuition to have going forwards!
While we're fixing things, the "mixed use of atomic and non-atomic operations" problem can be fixed by... making the heap use (relaxed) atomic operations. It's still a hack and a layering violation, but it should no longer be a theoretical memory model data race UB. It also shouldn't change the generated code, as the previous store was a 64-bit pointer that should already be atomic.
Incidentally, I also fixed a bunch of coercions to *mut, removed some unnecessary uses of mem::transmute, and generally should have fixed all of the Rust-level UB.
New benchmarks
We can now rerun the hacky benchmark from the previous attempt (which now very obviously doesn't test object deletion nor otherwise have particularly good invariant self-checking, but at least it'll be an apples-to-apples comparison):
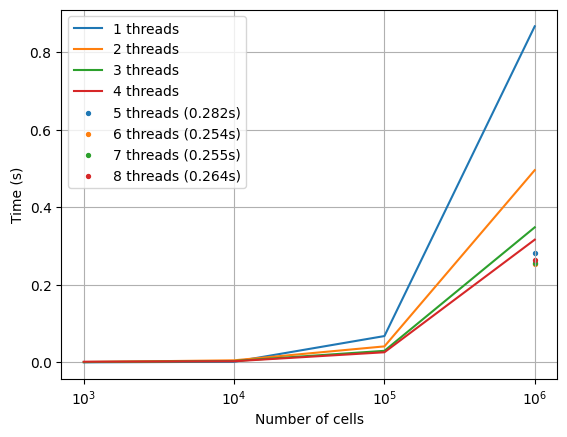
Some observations:
- This implementation completely beats the "slap
Arc<RwLock<>>everywhere" solution across all tested cases. This isn't too surprising as that implementation had tons of unnecessary work going on. - Our single-threaded performance beats the off-the-shelf "
sharded_slabplusRwLock" performance - With multiple threads but a tiny netlist, we perform worse than the
sharded_slabimplementation. It might be good to investigate why, although it might not matter at this scale (we're talking milliseconds in total). - At larger netlist sizes, we start to perform significantly better, and this continues to scale up until we increase the number of threads to 7-8 (although not linearly).
Going forward
Now I need to actually build out the "Galois system"-inspired graph stuff...